Kotlin Collections에서 지연 계산(lazy)의 이점을 알아보자.
개인 광고 영역
Kotlin collections을 사용할 때 주로 사용하는 map, filter 등을 사용한다. 이러한 함수의 동작 방법을 알아보고, 지연 처리의 장/단점을 알아보려고 한다.
이 글에서는 이전 글의 inline 관련 내용을 포함한다. 이미 알고 있다면 넘어가고, 이전 글이 궁금하다면 한 번 더 살펴보고 오면 좋을 듯하다.
Kotlin inline class와 inline functions을 알아보고, 적절하게 사용하는 방법을 살펴보자.
이 글에서 알아볼 내용
- collection 사용에 map, filter 등의 api를 알아본다.
- Collection에도 지연 계산이 가능한데, 지연 처리를 알아본다.
- inline을 활용하는 collection 확장 함수들이 성능이 더 좋을지, 지연 처리가 더 좋을지 살펴본다.
Sequence와 Iterable
코틀린의 모든 Collections은 Collections.kt 파일의 interface Iterable
MutableIterable, Collection, MutableCollection, List, MutableList, Set, MutableSet, Map, MutableMap이 모두 Iterable을 상속받고 확장하고 있는 형태이다.
/**
* Classes that inherit from this interface can be represented as a sequence of elements that can
* be iterated over.
* @param T the type of element being iterated over. The iterator is covariant on its element type.
*/
public interface Iterable<out T> {
/**
* Returns an iterator over the elements of this object.
*/
public operator fun iterator(): Iterator<T>
}
그리고 _Collections.kt 파일에 Iterable을 확장하는 extensions 들이 존재한다.
이러한 확장 함수들은 함수를 전달받아 처리하는 확장 함수 형태로 만들어져있다.
이전 글을 통해 확인할 수 있었지만 inline이 붙은 경우 이러한 코드를 모두 인라인 처리한다.
결국 우리가 사용하는 Collections 들은 기본적으로 inline을 통해 동작함을 알 수 있다.
/**
* Returns a list containing the results of applying the given [transform] function
* to each element in the original collection.
*
* @sample samples.collections.Collections.Transformations.map
*/
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
inline을 통해 동작하는 collections 확장 함수
Collections을 확장하여 사용하는 map, filter 등의 동작 방법을 알아보자.
아래와 같이 List를 하나 생성했다.
val item: IntRange = 1..10
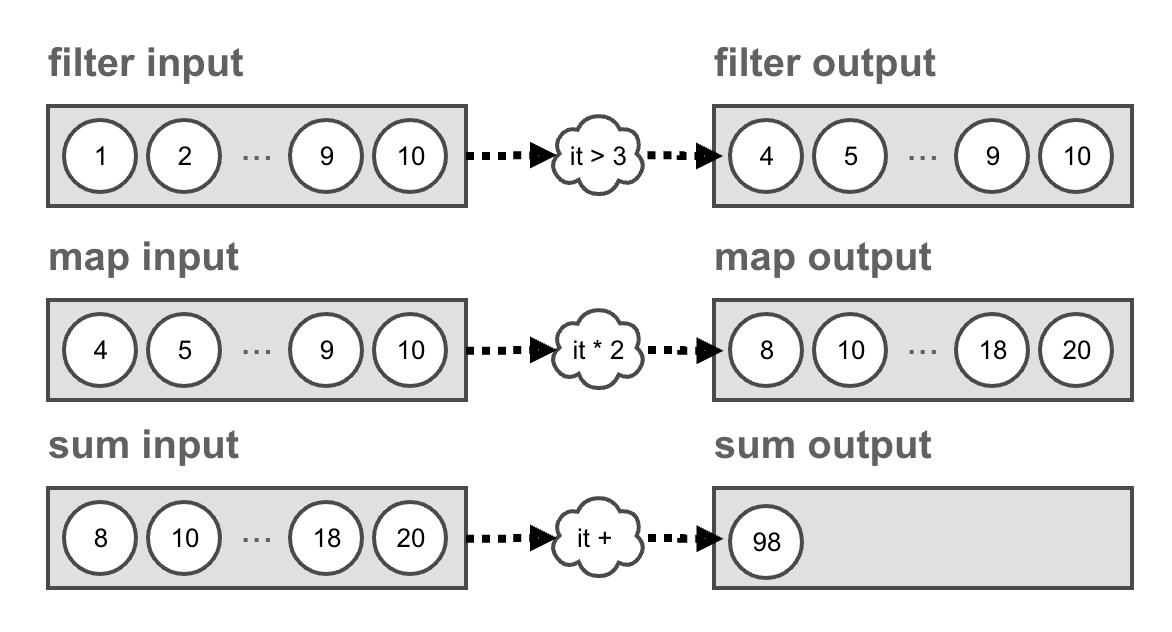
이를 활용해 filter로 3보다 큰 값을 필터 하여 * 2를 처리하는 코드를 작성해본다.
이 코드의 결괏값은 아래와 같이 나온다.
1~10까지의 모든 filter 결과
4~10까지의 모든 map 처리 결과
4~10까지의 * 2에 대한 sumBy 결과
그림으로 그리면 아래와 같은데, 순차적으로 실행함을 알 수 있다.
컬렉션을 디컴파일 해보자.
이러한 filter, map, sumBy는 모두 inline으로 만들어져있다. 디컴파일 결과에서도 다량의 코드를 볼 수 있는데, 너무 길어 일부 코드를 생략하고 중요한 부분만 아래 주석으로 표기한다.
@Test
public final void test() {
// 새로운 IntRange을 생성한다. 여기에는 1, 10까지의 값을 담는다.
IntRange item = new IntRange(var2, 10);
// filter의 결과를 담기 위한 새로운 컬렉션을 생성한다.
Collection destination$iv$iv = (Collection)(new ArrayList());
// 생략
// while 문으로 1, 10까지의 값을 루프 처리한다. 이때 Iterator의 hasNext를 이용해 체크한다.
while(var8.hasNext()) {
// 생략
System.out.print(var12);
if (it > 3) {
destination$iv$iv.add(item$iv$iv);
}
}
// map을 처리하기 위한 새로운 Collection을 다시 생성한다. 조건은 filter의 사이즈만큼 만든다.
destination$iv$iv = (Collection)(new ArrayList(CollectionsKt.collectionSizeOrDefault($this$sumBy$iv, 10)));
// while 문으로 이번엔 1, N 값 까지의 루프를 처리한다. 역시 Iterator의 hasNext를 이용한다.
while(var8.hasNext()) {
// 생략
System.out.print(var12);
Integer var15 = it * 2;
destination$iv$iv.add(var15);
}
// 최종 sum의 결괏값을 담기 위한 변수를 생성한다. 여기서는 for 문을 이용하는데, 로그 출력 용이다.
int sum$iv = 0;
for(Iterator var18 = $this$sumBy$iv.iterator(); var18.hasNext(); sum$iv += it) {
Object element$iv = var18.next();
it = ((Number)element$iv).intValue();
int var21 = false;
String var22 = "sum " + it + ' ';
var11 = false;
System.out.print(var22);
}
}
단순 디컴파일 결과물이니 참고만…
이 결과물에서는 결과적으로 2번의 새로운 리스트 생성을 볼 수 있고,
여기에서 사용한 collectionSizeOrDefault은 아래와 같다. this가 Collection을 상속받았다면 Iterable의 사이즈를 이용하여 초기화하고, 그렇지 않다면 초기 10으로 리스트를 생성한다.
10인 이유는 현재 디컴파일 결과물의 값을 보고 적은 것입니다. 단순 참고만 하세요.
/**
* Returns the size of this iterable if it is known, or the specified [default] value otherwise.
*/
@PublishedApi
internal fun <T> Iterable<T>.collectionSizeOrDefault(default: Int): Int =
if (this is Collection<*>) this.size else default
새로운 리스트를 생성한다
디컴파일 결과물에서 볼 수 있었는데, 매번 새로운 리스트를 생성한다. 리스트를 만드는 부분이 메모리 낭비를 만들 수 있다.
현재 코드에서는 딱히 성능의 이점도 없긴 하지만 더 큰 데이터를 처리하고 복잡한 로직이 포함되어 있다면 이런 방법은 오히려 느릴 수 있다.
10만 개의 값을 처리하는데 들어가는 시간을 측정해보자.
로컬 PC인 맥북 2017년 고급형 사양으로 동작하면 22ms가 걸렸고, Kotlin Web에서 동작하는 위 가상머신에서는 현시점 66ms가 걸렸다.
지연 계산(lazy)을 알아보자.
컬렉션을 사용할 때 map, filter의 결과를 즉시 새로운 리스트에 담음을 알 수 있다. 결국 map, filter, map … 등의 연속된 작업이 많아지면 그때마다 새로운 List를 생성하고, 결괏값을 임시 저장함을 알 수 있다.
장점은 중간중간 처리 결과가 필요하다면 이를 즉시 사용할 수 있다.
하지만 복잡도가 올라가면 올라갈수록 이는 좋은 경험을 제공하지는 않을 것 같다. 단순 Int의 1..100_000개의 아이템을 처리하는데도 2번의 새로운 리스트를 생성하고 sum을 함을 알 수 있다.
다행히 코틀린에서 지연 계산을 위한 sequence를 이용하여 지연 계산을 할 수 있다. 지연 처리를 알아보자.
sequence를 활용해보자.
위에서 작성한 filter, map, sumBy에 대한 코드 그대로 sequence에서 활용할 수 있는데, item 뒤에 filter 전에 asSequence()를 추가한다.
처음 작성했던 1부터 10까지의 결과를 처리하는 코드에 asSequence()만 추가했다.
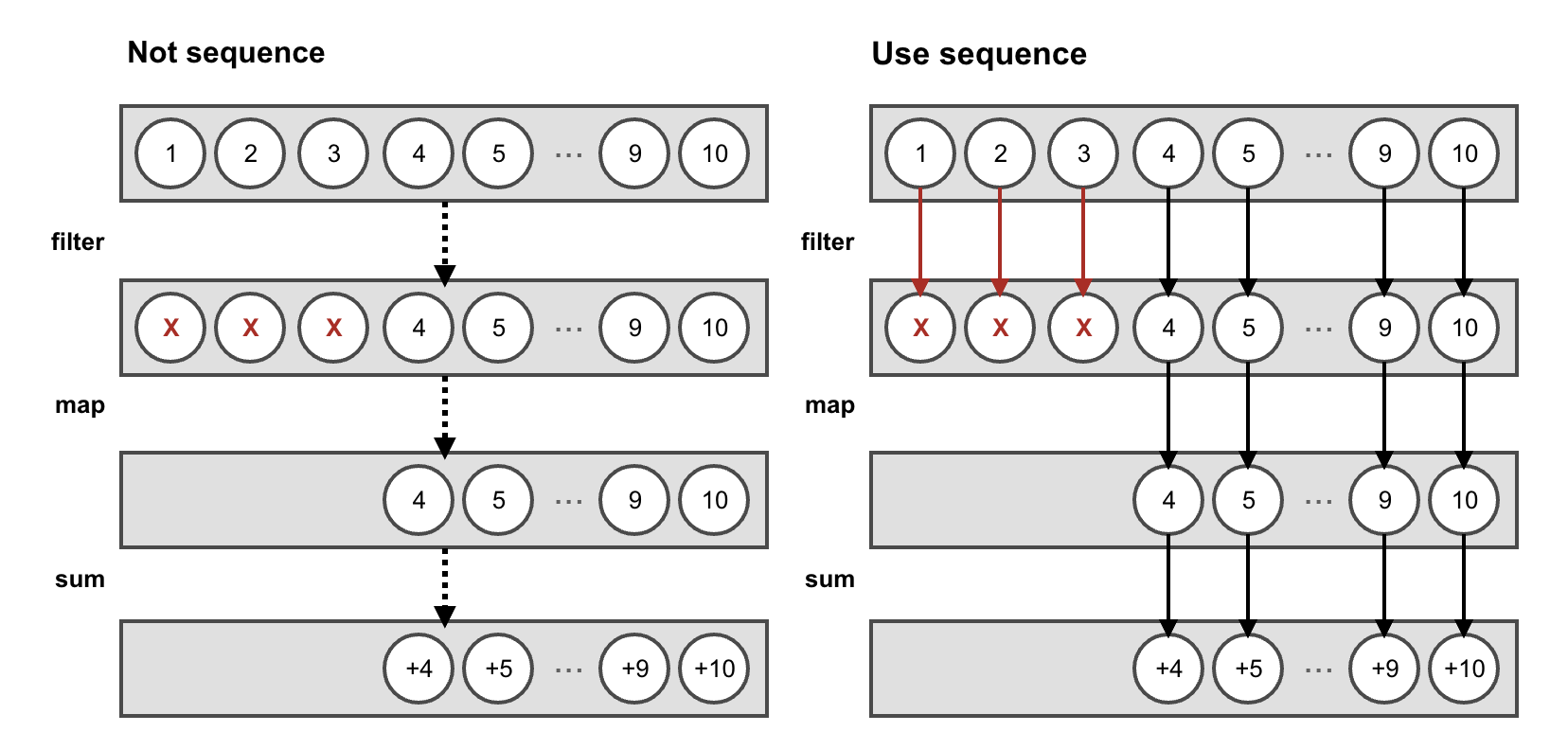
이 코드의 결과를 보면 기존과 다른게 보이는데, 기존엔 filter를 먼저 다하고, map을 이어서 처리하고, sum을 하는 과정을 거쳤으나, asSequence를 추가함으로써 아래와 같이 변경되었다.
filter 조건이 맞는다면 map을 처리하고, sum을 즉시 처리한다.
filter 1
filter 2
filter 3
filter 4 map 4 sum 8
filter 5 map 5 sum 10
filter 6 map 6 sum 12
filter 7 map 7 sum 14
filter 8 map 8 sum 16
filter 9 map 9 sum 18
filter 10 map 10 sum 20
디컴파일로 잠깐 보고 넘어가자.
디컴파일 결과는 단순 참고용으로 활용하여 아래처럼 가져와보았다.
지연 처리를 위해 Sequence 변수를 하나 생성한다. 이때 $this$sumBy$iv가 호출되지 않으면 생성자만 만들어지고, 동작은 하지 않는다.
만들어진 부분은 중간 연산을 위한 부분이고, 최종 연산을 적어주지 않으면 이 코드는 동작하지 않는다.
여기서는 중간 연산을 미리 $this$sumBy$iv로 만들어두고, 최종 연산인 for 문의 sum$iv += it에서 sum을 하는 것을 알 수 있다.
IntRange item = new IntRange(var2, 10);
Sequence $this$sumBy$iv = SequencesKt.map(SequencesKt.filter(CollectionsKt.asSequence((Iterable)item), (Function1)null.INSTANCE), (Function1)null.INSTANCE);
int $i$f$sumBy = false;
int sum$iv = 0;
int it;
for(Iterator var6 = $this$sumBy$iv.iterator(); var6.hasNext(); sum$iv += it) {
Object element$iv = var6.next();
it = ((Number)element$iv).intValue();
int var9 = false;
String var10 = "sum " + it + ' ';
boolean var11 = false;
System.out.print(var10);
}
String var14 = "sum " + sum$iv;
$i$f$sumBy = false;
System.out.print(var14);
추가로 sumBy가 아닌 sum()을 사용하면 아래와 같이 즉시 결과를 반환하는 것처럼 보일 수 있다.
int sum = SequencesKt.sumOfInt(SequencesKt.map(SequencesKt.filter(CollectionsKt.asSequence((Iterable)item), (Function1)null.INSTANCE), (Function1)null.INSTANCE));
지연 계산은 List를 생성하지 않는다.
디컴파일 결과물에서 알 수 있듯 지연 처리에서는 중간 리스트를 생성하지 않고, 즉시 처리함을 알 수 있다.
결과적으로 아래 그림과 같다. 왼쪽은 기존 Sequence를 적용하지 않고 컬렉션을 다루었을 때이고, 오른쪽은 sequence를 추가했을 때이다.
지연 처리의 성능은?
지연 처리의 성능을 2가지 코드로 측정해본다. 1..10까지의 성능과 1..100_000까지의 성능을 각각 체크해본다.
개인적으로 사용하는 맥북 2017년 15인치 고급형에서 동작한 결과이다.
1..10
getMeasureTimeMillis(1..10) 7
getSequenceMeasureTimeMillis(1..10) 8
1..100_000
getMeasureTimeMillis(1..100_000) 16
getSequenceMeasureTimeMillis(1..100_000) 15
그리고 가상 kotlin 머신에서의 동작 결과이다.
1..10
getMeasureTimeMillis(1..10) 16
getSequenceMeasureTimeMillis(1..10) 17
1..100_000
getMeasureTimeMillis(1..100_000) 41
getSequenceMeasureTimeMillis(1..100_000) 34
몇 번 더 돌렸지만 유사한 결과가 나온다. 그리고 명확한 차이를 보려면 1_000_000으로 수정하여 테스트해야 명확한 결과를 볼 수 있는데, 아래와 같다.
참고로 가상 머신에서는 sequence를 하지 않고 동작하는 첫 번째 함수가 오류가 발생한다. Evaluation stopped while it’s taking too long️
1..1_000_000
getMeasureTimeMillis(1..1_000_000) 144
getSequenceMeasureTimeMillis(1..1_000_000) 38
처리에 대한 결론
- 데이터가 단순하다면 오히려 sequence를 적용하지 않는 편이 좋다.
- 늦은 처리가 필요한 경우와 그렇지 않은 경우를 구분하자
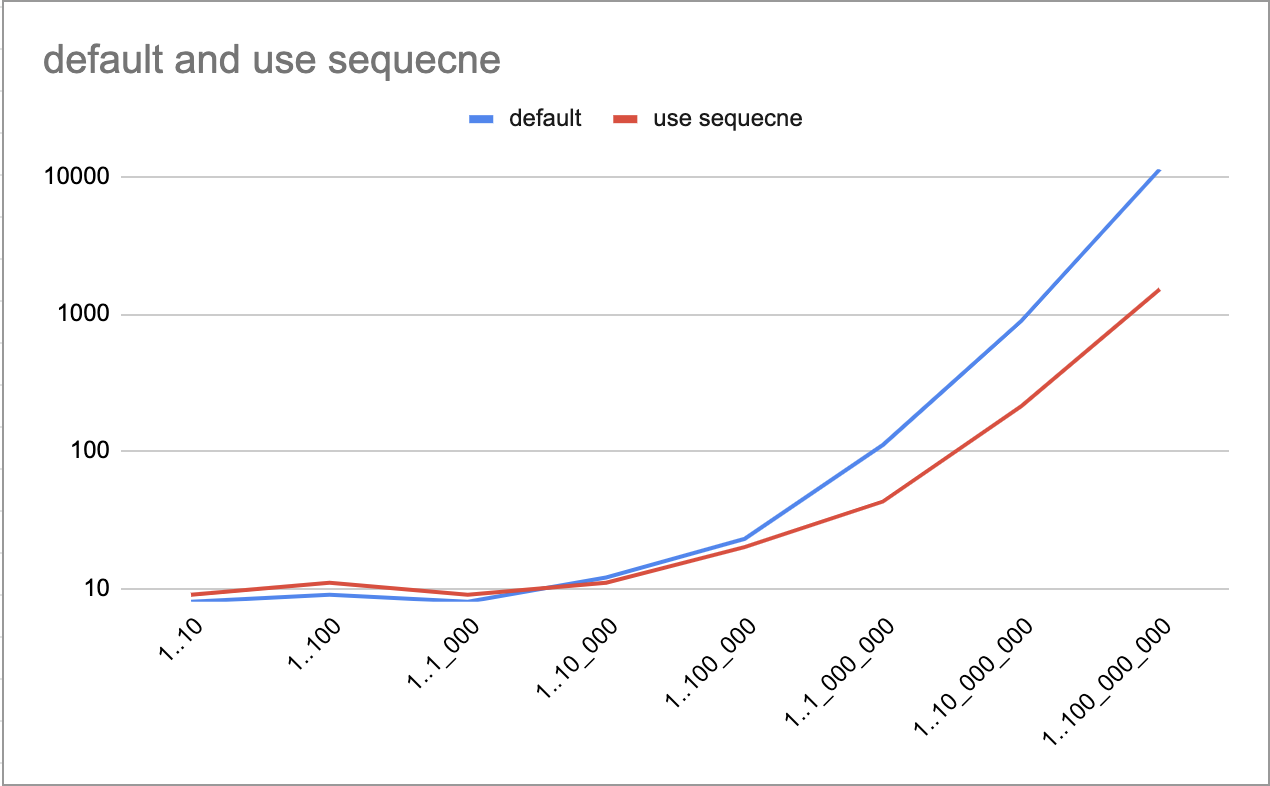
IntRange를 다양하게 테스트한 결과물 두 개를 추가한다. 이 테스트는 단순 반복을 통해 얻은 결과물이므로 참고 용이다.
다음의 결과물대로라면 최소 1,000번에서 10,000번의 데이터 처리가 되었을 때 sequence 적용했을 때와 아닐 때의 구분이 생긴다.
데이터의 복잡도와 데이터처리의 복잡도에 따라서 결과물은 다르게 나올 수 있으니 단순 참고하길
테스트 환경
- Android Studio 4.2 Preview, 메모리 4GB
- 2017년 15인치 맥북
- CPU : 2.9 GHz Quad-Core Intel Core i7
- RAM : 16 GB 2133 MHz LPDDR3
- UnitTest 코드 기준으로 테스트
실제 기기에서는 어떨까?
- Pixel 4a 기준 테스트 결과
- Coroutines Dispatchers IO에서 동작한 결과물
- 역시 단순 테스트
결과적으로 1_000_000번의 단순 filter, map, sumBy를 사용한 경우는 메모리 부족(OutOfMemory) 오류 발생으로 인해 종료되었고, sequence를 사용한 경우에 만 정상적인 작업으로 결과 확인이 가능했다.
실제 기기에서는 10_000개 이상인 경우부터 Sequence의 활용이 눈에 띄고, 그 아래는 비슷하거나 오히려 느린 결과를 가져온다.
![]()
시퀀스 대신 사용할 방법은?
시퀀스 대신 사용하는 방법은 for 문을 직접 돌리고 if 문을 직접 처리하는 방법이다.
사실 이 방법도 성능상 이점이 있다. Sequence처럼 지연 계산 방법에 해당한다.
이 결과는 필자가 사용하는 PC에서 5ms의 시간이 나왔다.
결국 필요에 따라 사용해야 한다.
결국 사용하는 환경에 따라 필요한 방법을 찾아서 사용하는 게 좋다. 지연 계산이 필요하다면 sequence를 활용하면 좋고, 단순하다면 collection을 이용해 코드를 줄일 수 있다. 그래도 난 전통적인 방법이 좋다면 직접 작성하는 것도 하나의 방법이다.
- 샘플처럼 단순한 처리라면 sequence 보다 inline을 활용하는 collection 확장이 좋다.
- 로직이 복잡하고, 해야 할 작업이 많다면 sequence를 활용하는 게 나쁘지는 않다.
- 메모리 활용도를 생각해보고 결정해야 한다.
결국 답은 없지만 필요한 데이터를 단순 테스트로 좀 더 좋은 결과를 만들 수 있으니 참고하시면 좋을 것 같다.
이 글만 보기 아쉽죠. Effective Kotlin 더 보기
지금까지 작성한 EffectiveKotlin 관련 글은 태그로 모아 링크를 추가한다.
Comments